Exemplo 3. Realizar a soma dos 100 primeiros números
soma =0i =1while (i <=100) { soma = soma + i i = i +1}print(soma)
[1] 5050
Encerramos os 5 fundamentos da lógica da programação!!!
Function
IF
ELSE
FOR
WHILE
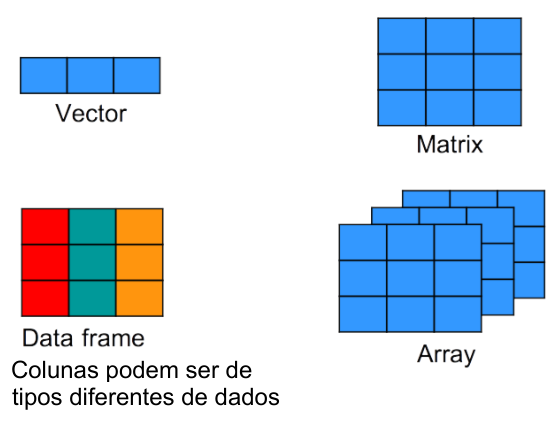
Retornando às estruturas de dados do R
VETOR: série de números (ou caracteres). Vetor tem uma dimensão.
#### Exemplos:v =c(1,2,3,4,5)vs =c('A','B','C','D')#### Funções vetoriaislength(v)sum(v)#### Índices de vetoresv[1] # Primeiro elementov[length(v)] # Último elementov[3] =99#Atribuir um elemento individual#### Filtragem lógica com operadores booleanosv[(v <3) & (v !=0 )]
MATRIZ: série de vetores do mesmo tipo (numérico ou de caracteres). Matriz tem 2 dimensões (linhas e colunas).
Em array, todos os dados são do mesmo tipo, assim como as matrizes.
Array é pouco usada em problemas aplicados.
Array é usada em conceitos matemáticos multi-dimensionais.
Não se preocupe muito com elas, apenas entenda o conceito de multi-dimensional, baseado em Linhas X Colunas X Camadas, e que isso pode mais mais dimensões ainda.
Criando arrays
x =1:24A =array(x, dim =c(3,4,2)) # Array 3D: (linhas, colunas, "camadas")A
id sexo altura peso imc
1 1 F 1.58 62 24
2 2 M 1.87 91 26
3 3 M 1.75 78 25
4 4 F 1.72 72 24
Índices em dataframes: Assim como matrizes, dataframes são bidimensionais (Linhas X Colunas).
df1
id sexo altura peso imc
1 1 F 1.58 62 24
2 2 M 1.87 91 26
3 3 M 1.75 78 25
4 4 F 1.72 72 24
df1[1,2] # Extrai o elemento da linha 1 e coluna 2.
[1] "F"
df1[3,] # Extrai apenas a terceira linha.
id sexo altura peso imc
3 3 M 1.75 78 25
df1[,2] # Extrai apenas a segunda coluna.
[1] "F" "M" "M" "F"
df1$sexo # Também extrai a segunda coluna
[1] "F" "M" "M" "F"
df1
id sexo altura peso imc
1 1 F 1.58 62 24
2 2 M 1.87 91 26
3 3 M 1.75 78 25
4 4 F 1.72 72 24
df1[c(1,3),] # Extrai a linha 1 e a linha 3 inteiras.
id sexo altura peso imc
1 1 F 1.58 62 24
3 3 M 1.75 78 25
df1[c(1,3),2] # Extrai a linha 1 e a linha 3 da segunda coluna.
[1] "F" "M"
df1[1:3,1:3] # Extrai da linha 1 até a linha 3 das colunas de 1 a 3.
id sexo altura
1 1 F 1.58
2 2 M 1.87
3 3 M 1.75
Como o vetor df1 foi criado com os nomes das colunas, podemos selecioná-las pelo nome.
df1
id sexo altura peso imc
1 1 F 1.58 62 24
2 2 M 1.87 91 26
3 3 M 1.75 78 25
4 4 F 1.72 72 24
# Selecionando todas as linhas e 2 colunas.df1[,c('id','sexo')]
id sexo
1 1 F
2 2 M
3 3 M
4 4 F
Os poderosos filtros em dataframes no R
Os filtros funcionam tal como em vetores e matrizes, aplicados separadamente às linhas e colunas do dataframe.
df1
id sexo altura peso imc
1 1 F 1.58 62 24
2 2 M 1.87 91 26
3 3 M 1.75 78 25
4 4 F 1.72 72 24
# Selecionando as linhas com imc > 24df1[df1$imc >24, ]
id sexo altura peso imc
2 2 M 1.87 91 26
3 3 M 1.75 78 25
df1
id sexo altura peso imc
1 1 F 1.58 62 24
2 2 M 1.87 91 26
3 3 M 1.75 78 25
4 4 F 1.72 72 24
# Selecionando as linhas das mulheres com peso < 77df1[(df1$sexo=='F') & (df1$peso <77) , ]
id sexo altura peso imc
1 1 F 1.58 62 24
4 4 F 1.72 72 24
# Selecionando as linhas dos homens com peso > 80 e mostrando apemas o id e imc.df1[(df1$sexo=='M') & (df1$peso >80) , c('id','imc')]
id imc
2 2 26
Exercícios de dataframes
Considere o seguinte dataframe proveniente de uma campanha de amostragem de bentos:
local =c('L1','L1','L1','L2','L2','L2')amostra =c('a1','a2','a3','a1','a2','a3')abund =c(23,45,0,56,0,25)
Com esses dados, crie um dataframe chamado “dados” e responda:
1 - Extraia o vetor correspondente à primeira coluna.
2 - Extraia o elemento da segunda linha e terceira coluna.
3 - Extraia apenas as linhas correspondentes aos locais L1.
Extraia apenas as linhas dos locais L2 em que a abundância seja maior que 30.
Extraia apenas as colunas amostra e abund dos locais L1 em que a abundância seja diferente de zero.
DESAFIO: Crie uma nova coluna no dataframe chamada pres_aus com valores de 1 e 0 para presença e ausência de abundância.
Manipulação de arquivos no R para abrir planilhas do Excel como dataframe no R
Working dir no RStudio: como manipular.
Criar uma planilha no Excel, como nome de coluna e salvar como formato csv.
No R, abrir o arquivo usando a função read.csv ou read.csv2.
Alternativamente, é possível abrir um arquivo Excel (xls ou xlsx) diretamente no R, usando o pacote readxl.